Langchain is a framework that allows you to create an application powered by a language model, in this langChain Tutorial Crash you will learn how to create an application powered by Large Language Models (LLMs) and we will cover all the essential features of this framework.
Overview:
- Installation
- LLMs
- Prompt Templates
- Chains
- Agents and Tools
- Memory
- Document Loaders
- Indexes
Installation :
`pip install langchain`
LLMs :
LLMs are a kind of natural language processing (NLP) technology that uses deep learning to generate human-like language, if you are not familiar With LLms, you might hear about a popular example called: chatgpt.
Chatgpt is a language model developed by OpenAi and it was trained on a large amount of text data which allows it to understand the patterns and generate answers to the question
Langchain is a Python framework that provides different types of models for natural language processing, including LLMs, These LLMs are specifically designed to handle unstructured text data and provide answers to user queries.
See all LLM providers.
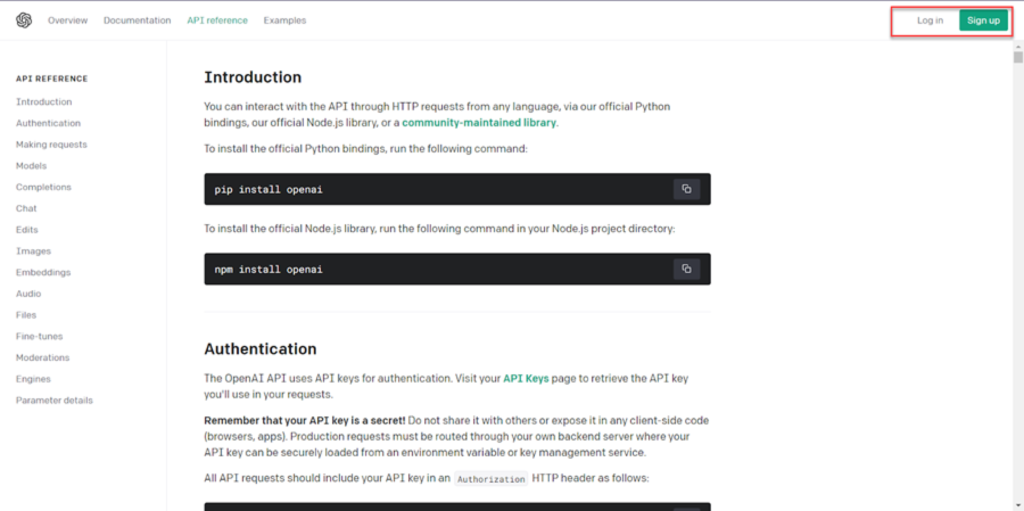
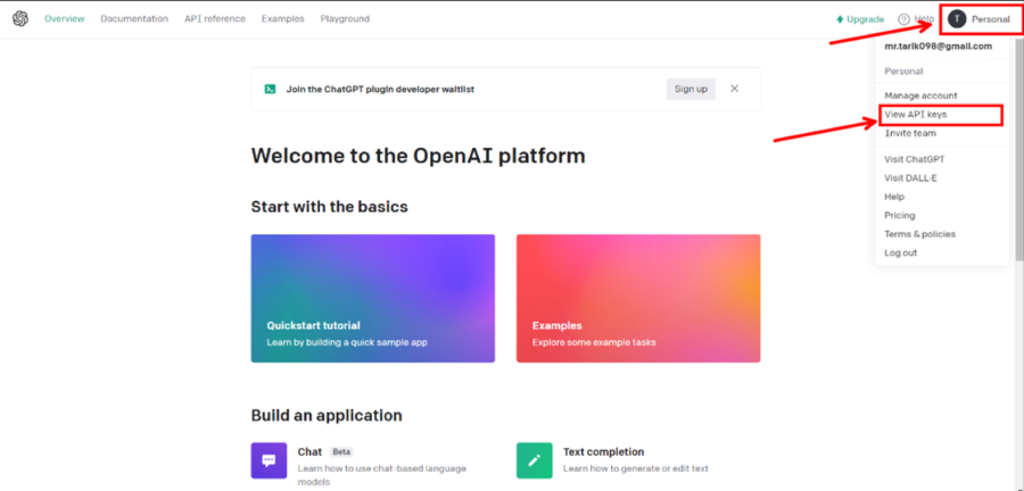
`pip install openai`
`import os
os.environ["OPENAI_API_KEY"] ="YOUR_OPENAI_TOKEN"
from langchain.llms import OpenAI
LLM = OpenAI(temperature=0.9) # model_name="text-DaVinci-003"
text = "give me 5 python project "
print(LLM(text))
pip install huggingface_hub
os.environ["HUGGINGFACEHUB_API_TOKEN"] = "YOUR_HF_TOKEN"
from langchain import HuggingFaceHub
# https://huggingface.co/google/flan-t5-xl
llm = HuggingFaceHub(repo_id="google/flan-t5-xl", model_kwargs={"temperature":0, "max_length":64})
llm("Who won the FIFA World Cup in the year 1994?")`
Prompt Templates
what exactly are prompt templates for?
I use prompt templates to structure my input to give it to the AI model, the reason is to guide the Ai model to output in a specific direction to make sure a more consistent and desired response.
Why would I use this versus just chatting with the bot directly as a user like the ChatGPT UI?
The main difference between template and chat directly with chatgpt (like chatgpt ui) chatgpt UI allows for general conversation and is excellent for that purpose. Still, when you need more control, consistency, efficiency, or complexity that prompt templates come in handy right.
This feature allows developers to use PromptTemplates to construct prompts for user queries, which can then send to LLMs for processing
llm("Can joe biden have a conversation with George Washington?")
Most of the time we don’t want to paste the question directly into the model like this
Output
No, it is impossible for Barack Obama to have a conversation with George Washington as George Washington passed away in 1799.
How to write a better Prompt:
The better way to design the prompt is to Say
prompt = """Question: Can joe biden have a conversation with George Washington?
Let's think step by step.
Answer: """
LLM(prompt)
output
No, Barack Obama and George Washington cannot have a conversation because George Washington is no longer alive.
PromptTemplates can help you accomplish this task:
from langchain import PromptTemplate
template = """Question: {question}
Let's think step by step.
Answer: """
prompt = PromptTemplate(template=template, input_variables=["question"])
prompt.format(question="Can joe biden have a conversation with George Washington?")
llm(prompt)
I you want to run the code you will get the error because we can not pass the prompt directly to LLM
So we are going to use chain to pass to LLms
Chains
Chains offer a way to integrate diverse components into a unified application. For example, a chain can be created that takes user input, processes it using a PromptTemplate, and then feeds the structured response to a Language Learning Model (LLM). More intricate chains can be formed by interlinking numerous chains with other components.
from langchain import LLMChain
llm_chain = LLMChain(prompt=prompt, llm=llm)
question = "What are the steps to start a successful online business?"
print(llm_chain.run(question))
Agents and Tools
Agents determine which actions to take and in what order. Agents can be incredibly powerful when used correctly. To successfully utilize agents, you should understand the following concepts:
Tool: A function that executes a specific task. This can be things like performing a Google Search, using another chain, or another task. See available Tools.
LLM: The language model powering the agent.
Agent: The agent to use. See also Agent Types.
from langchain.agents import load_tools
from langchain.agents import initialize_agent
pip install Wikipedia
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
tools = load_tools(["Wikipedia", "LLM-math"], llm=llm)
agent = initialize_agent(tools, LLM, agent="zero-shot-react-description", verbose=True)
agent.run("Can you explain the concept of blockchain technology?”)
Memory
Memory refers to the concept of persisting state between calls of a chain or agent. LangChain provides a standard interface for memory, a collection of memory implementations, and examples of chains and agents that use memory.
Why Memory is Important?
Memory allows the model to maintain the context of a conversation. Without memory, each user prompt user would be processed in isolation
from langchain import OpenAI, ConversationChainM
llm = OpenAI(temperature=0)
conversation = ConversationChain(llm=llm, verbose=True)
conversation.predict(input="Hi there!")
conversation.predict(input="Can we talk about BlockchainI?")
conversation.predict(input="I'm interested in Solona.")
Document Loaders
Combining language models with your own text data is a powerful way to differentiate them. The first step in doing this is to load the data into “Documents” – a fancy way of saying some pieces of text. The document loader is aimed at making this easy.
See all available Document Loaders.
from langChain.document_loaders import NotionDirectoryLoader
loader = NotionDirectoryLoader("Notion_DB")
docs = loader.load()
Indexes
Indexes refer to ways to structure documents so that LLMs can best interact with them. This module contains utility functions for working with documents, different types of indexes, and then examples for using those indexes in chains.
- Embeddings: Embeddings are a measure of the relatedness of text strings, and are represented with a vector (list) of floating point numbers.
- Text Splitters: When you want to deal with long pieces of text, it is necessary to split up that text into chunks.
- Vector databases store and organize special codes that represent the meaning and context of words, sentences, and documents in a way that helps search engines provide better and more relevant results. See available vectorstores.
import requests
url = "https://raw.githubusercontent.com/hwchase17/langchain/master/docs/modules/state_of_the_union.txt"
res = requests.get(url)
with open("state_of_the_union.txt", "w") as f:
f.write(res.text)
# Document Loader
from langchain.document_loaders import TextLoader
loader = TextLoader('./state_of_the_union.txt')
documents = loader.load()
# Text Splitter
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
pip install sentence_transformers
# Embeddings
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings()
#text = "This is a test document."
#query_result = embeddings.embed_query(text)
#doc_result = embeddings.embed_documents([text])
pip install faiss-cpu
from langchain.vectorstores import FAISS
db = FAISS.from_documents(docs, embeddings)
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query)
print(docs[0].page_content)
# Save and load:
db.save_local("faiss_index")
new_db = FAISS.load_local("faiss_index", embeddings)
docs = new_db.similarity_search(query)
print(docs[0].page_content)
Conclusion :
LangChain offers a comprehensive approach to building applications powered by generative models and LLMs. By integrating core concepts from data science, developers can create innovative ideas which are beyond traditional metrics by leveraging multiple components, and prompt templates.
As technology advances, more complex elements, including chat interfaces, are incorporated into agents, providing more comprehensive support in many different use cases.
Whether you’re developing chatbots, sentiment analysis tools, or any other NLP application, LangChain will be your best helper to unlock the full potential of your data. As advancements in Natural Language Processing (NLP) technology continue growing, platforms such as Langchain will only become more and more valuable
All the code will be found on GitHub
Reference: